


从Stable diffusion上线以来,我们一直使用的是秋叶的WebUI版本,它的界面简单易用,方便初学者上手。但webUI的缺点在于,工作流程的逻辑不是很清晰,很多时候往往会漏掉一些重要的参数,而且底层架构比较复杂,导致了它对于用户配置需求很高。特别是当SDXL出来之后,很多人都无法在webUI上正常运行,为了能更好的适应未来SD的发展,今天来给大家介绍一下ComfyUI。
安装
我们先来讲解一下ComfyUI的本地部署,和初步的一个使用方法。ComfyUI下载的github链接:https://github.com/comfyanonymous/ComfyUI#installing,大家也可以去我的网盘里下载一键启动压缩包。
下载完后,将文件解压到一个没有中文的路径下。

共享模型
已经装过webUI的小伙伴看好了,模型、lora以及controlnet等占硬盘空间大的模型文件,我们不需要再重装一遍了,可以使用一个方法来让ComfyUI和webUI之间进行模型共享。
我们先找到comfyUI目录下的“extra_model_paths.yaml.example”文件。
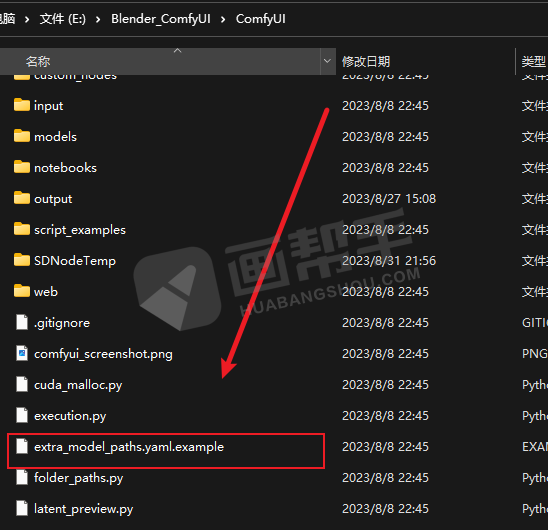
将该文件的后缀“.example”去掉,然后用记事本打开。
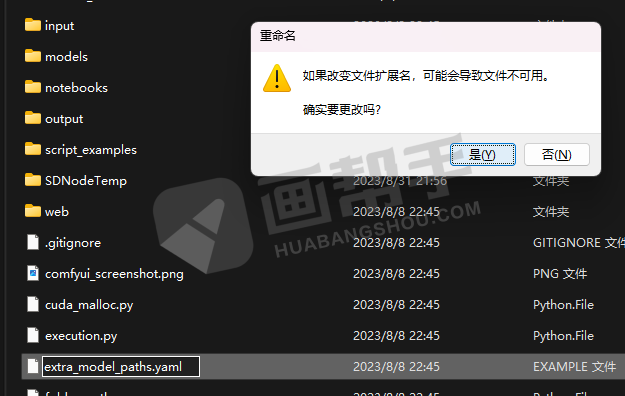
将“base_path”后面的路径改为电脑里面webUI的路径,改完之后保存就可以了。
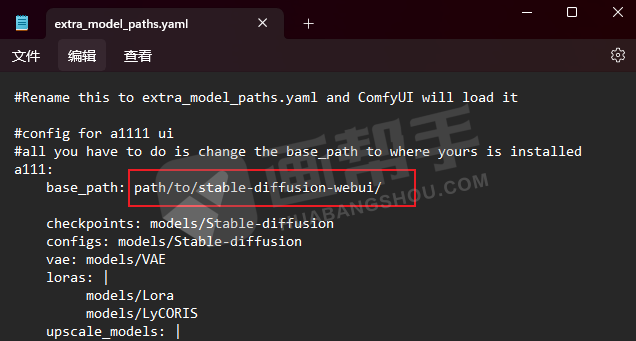
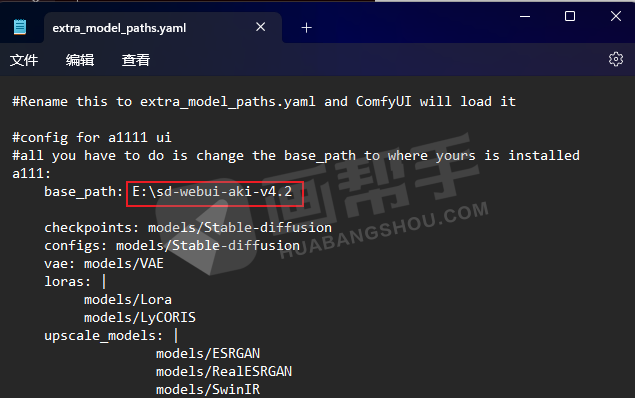
这样共享就设置好了,双击【run nvidia gpu.bat】启动。如果你的电脑是cpu比较好的话,可以点击【run cpu.bat】。
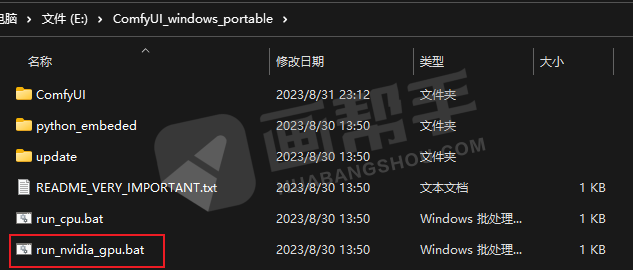
可以感受到的是,comfyUI的启动是比webUI要快的,页面打开之后会有一个初始工作流。
点击模型选择,就可以看到所有我们之前webUI的模型了,不需要再重新安装,节省了大量的空间。
建立第一个工作流
接下来,我们先来了解一下ComfyUI的工作原理。如果已经比较熟悉webUI参数的同学,应该可以很容易理解。
ComfyUI就是将每一个参数变成了一个模块,我们又称之为节点,通过节点与节点之间的串联,形成一个完整的工作流程。
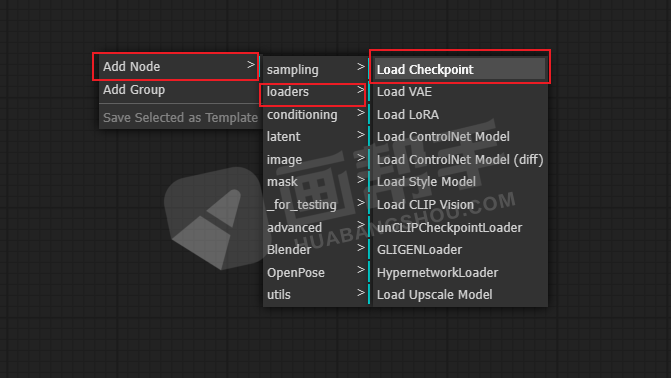
这里我们清空所有节点,从零开始。先加载一个模型选择器的节点,右键点击空白处,选择【add node】——【loaders】——【load checkpoint】。
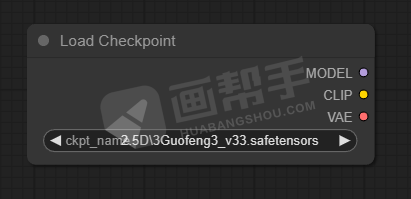
就可以生成这样一个节点,可以选择我们安装好的大模型,并且后面还有三个连接点,可以指向下一个模块。
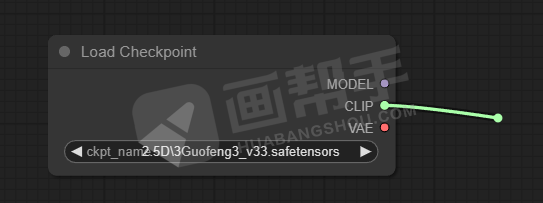
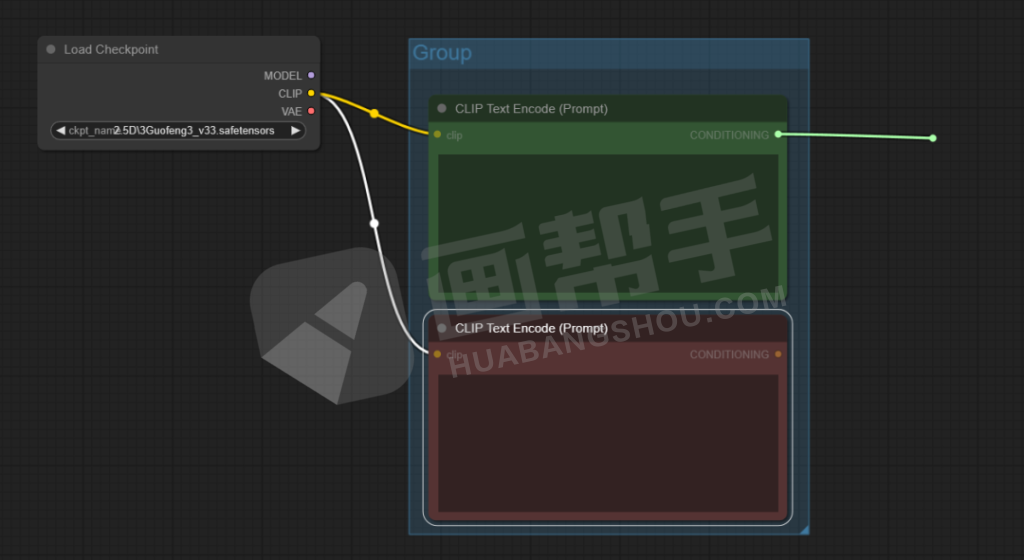
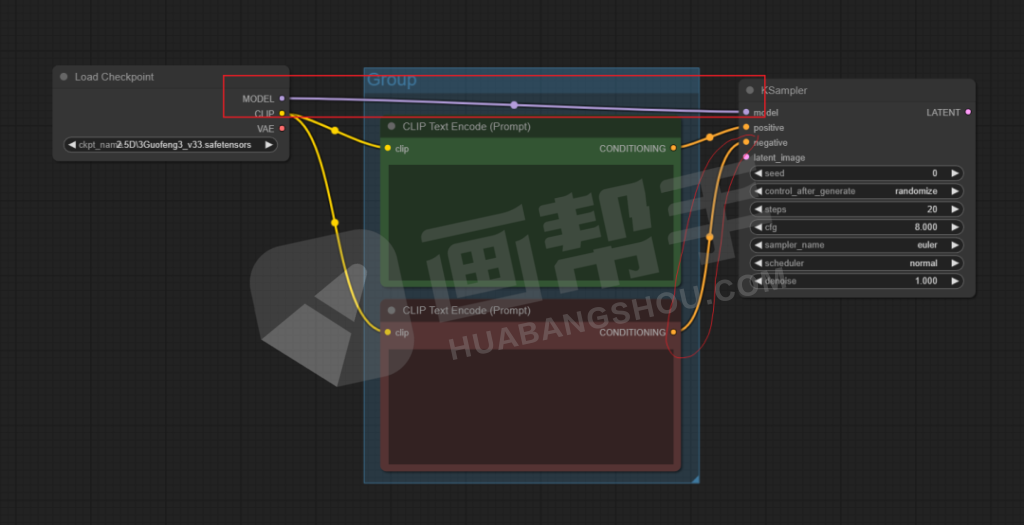
我们按住clip后面的点进行拖拽,点击【CLIPTextEncode】,得到一个提示词输入框。
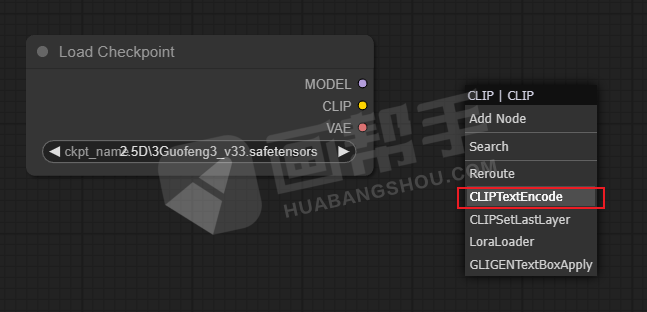

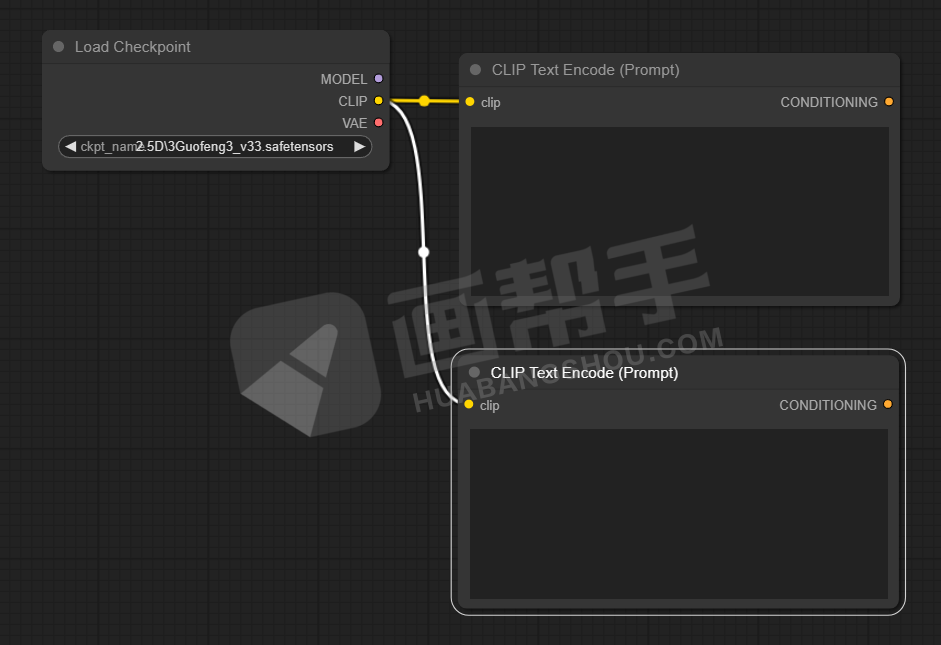
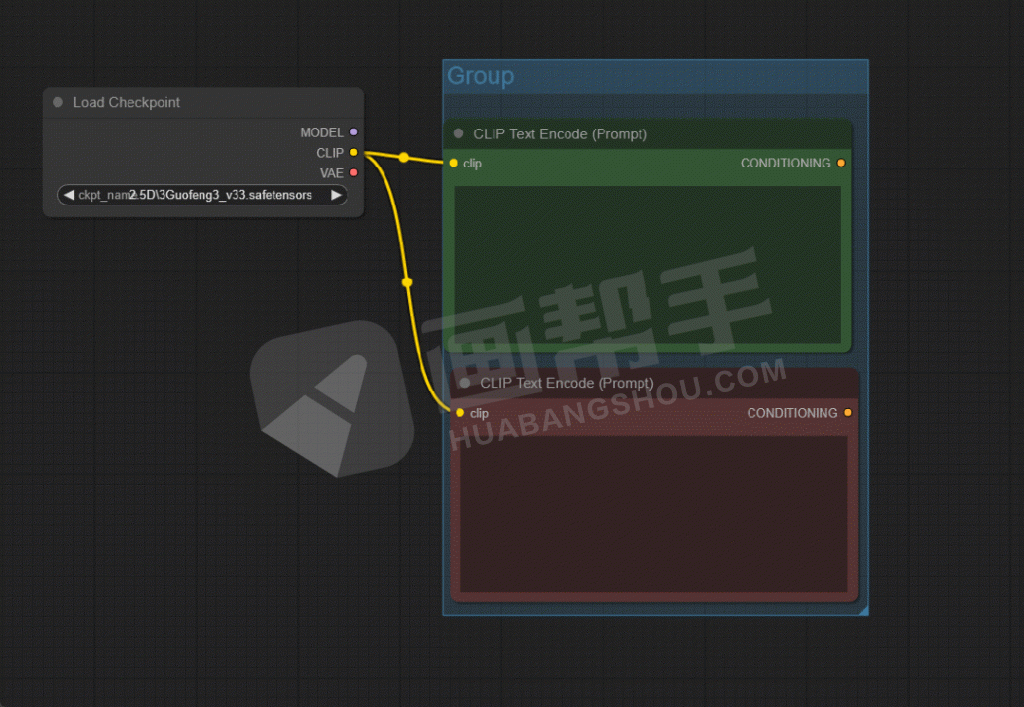
同理,我们可以再加一个提示词框,形成了一个正向提示词和一个负向提示的架构。
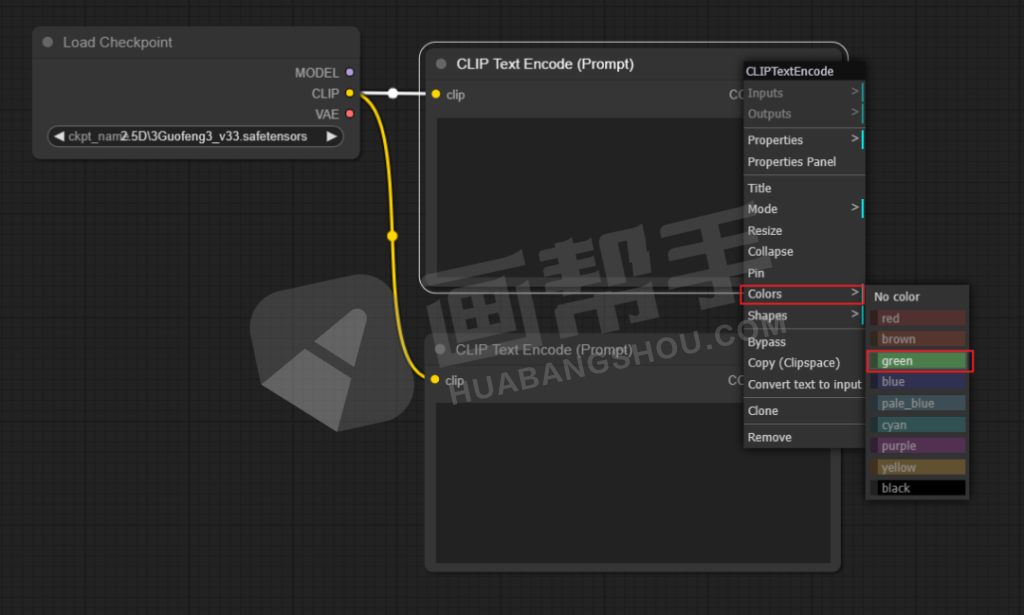
为了后面更方便使用,我们还可以点击右键,给节点添加颜色。比如,正向提示词为绿色,负向提示词为红色。
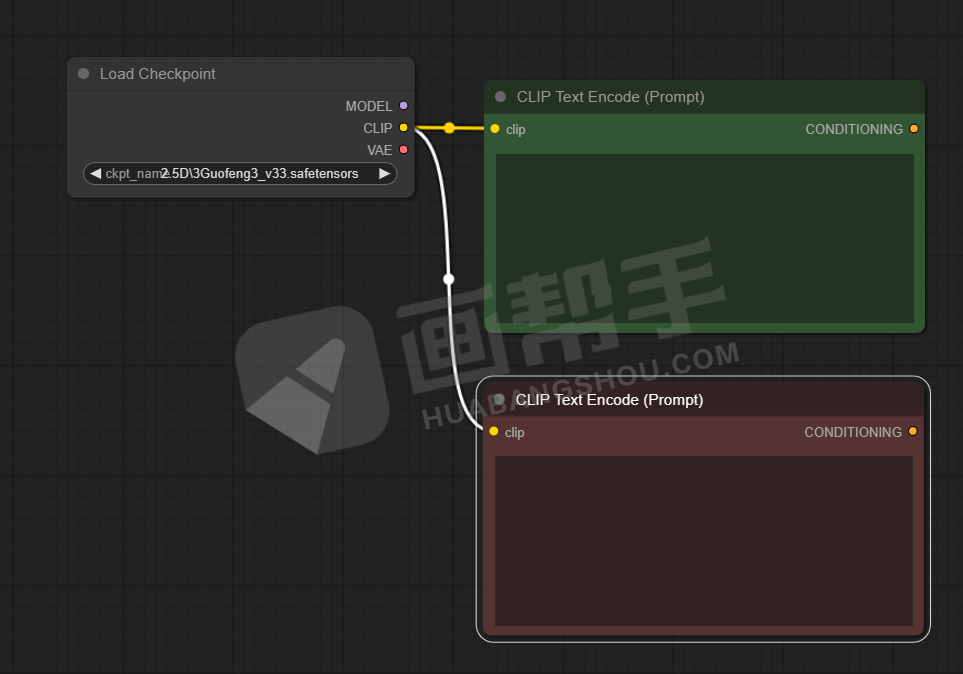
为了方便管理,我们可以再添加一个组,放在组里的节点可以一起移动,方便了我们后面做一些模组管理。
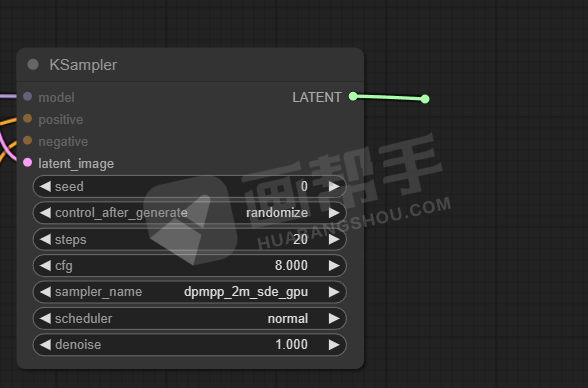
接下来,我们需要使用采样器来给提示词内容添加噪声。从提示词节点后面再次拉出一根线,选择【KSampler】。
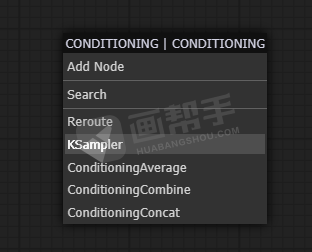
这里面可以看到我们熟悉的参数:种子数、迭代步数、CFG、采样器等等。我就不做过多解释了,学过webUI的理解起来都很容易。
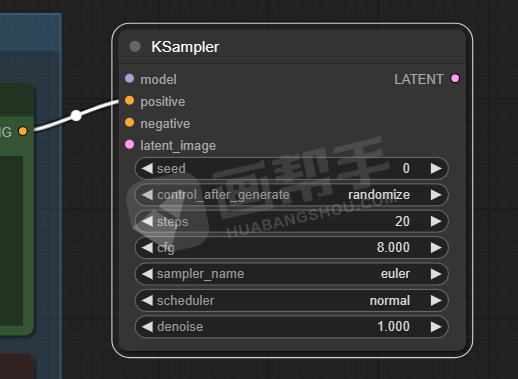
这时,我们就可以将模型和负向提示词全部连上了。
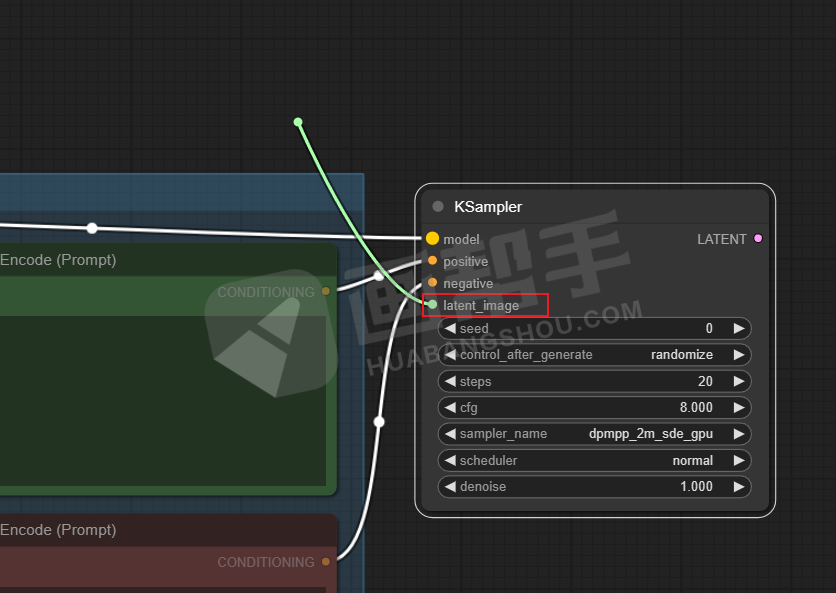
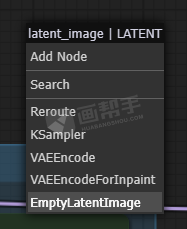
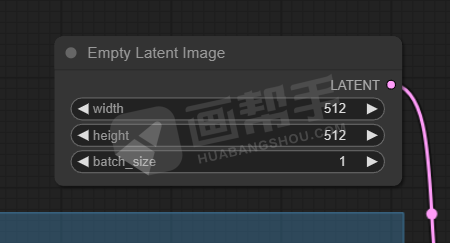
接下来,设置输出图片尺寸,从【latent image】中拉出一个节点,选择【EmptyLatentImage】。
我们就可以在这个节点里面填写想要输出的尺寸,和一次性生成的数量。
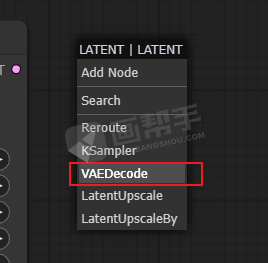
接下来,我们要使用VAE来对之前的噪声进行解码,从【LATENT】中拉出一个节点,选择【VAEDecode】。
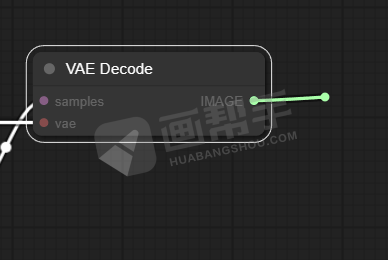
建立好之后,将最开始的VAE节点与之相连。

最后,我们要输出图片,从VAE解码的节点中的【IMAGE】中拉出一根线。选择【SaveImage】,这样我们每次生成的图片都会存放在output文件夹里面。如果不想每次都保存,可以选择下面的【PreviewImage】。
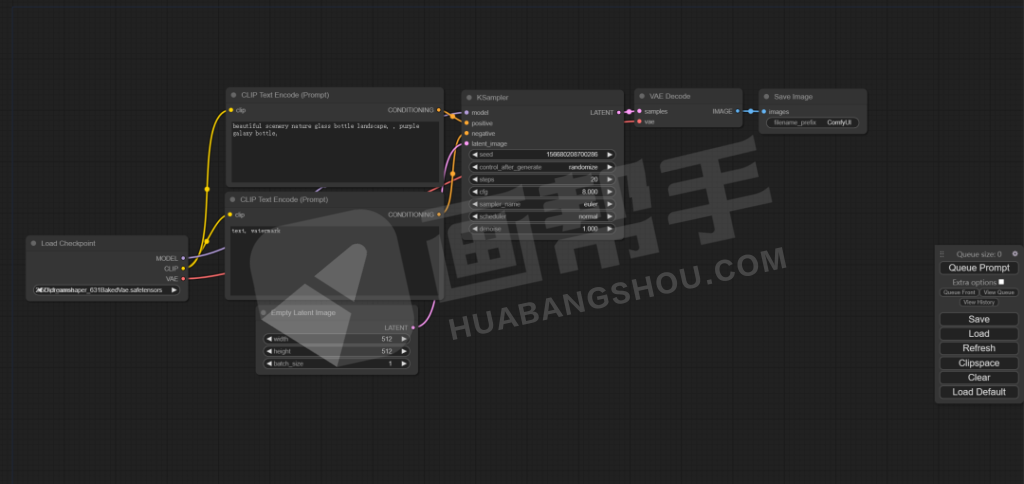
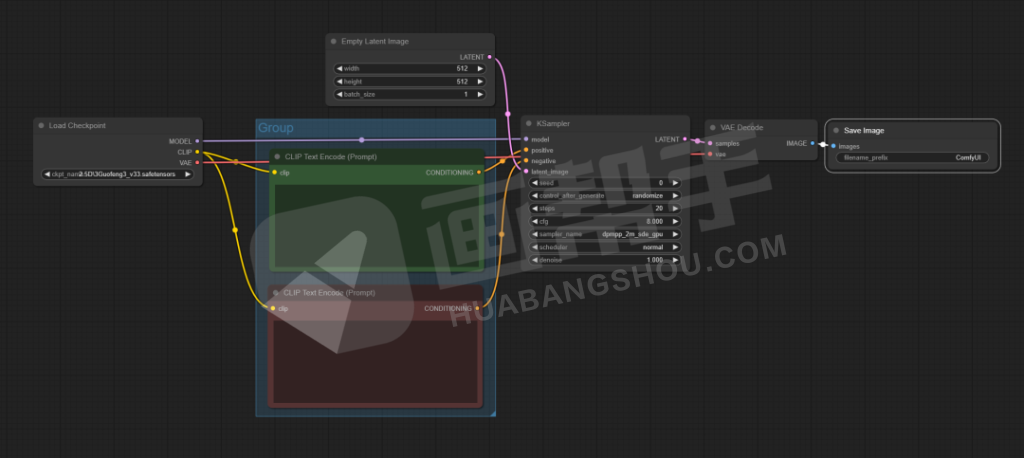
到此为止,我们就建立好了一个简单的文生图工作流。
可以在右侧点击【Save】,保存这个工作流,那么下一次我们要进行文生图操作的时候,只需要载入这个工作流就可以了,不用再重复搭建。
我们填入一套提示词,来测试一下这套工作流的使用情况,点击【Queue Promot】开始渲染。
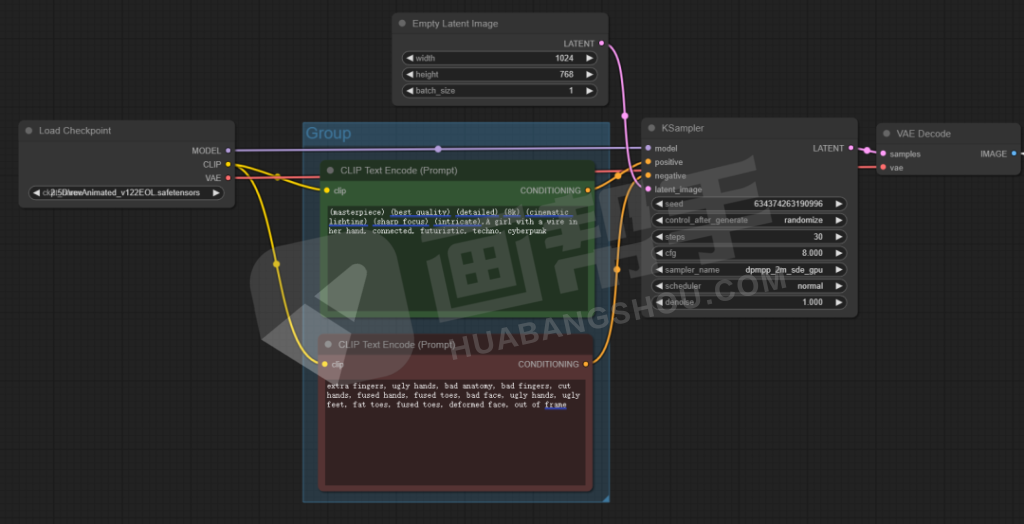
出图完成,说明我们的工作流可以正常运行了,撒个花吧,庆祝我们的第一次搭建成功。
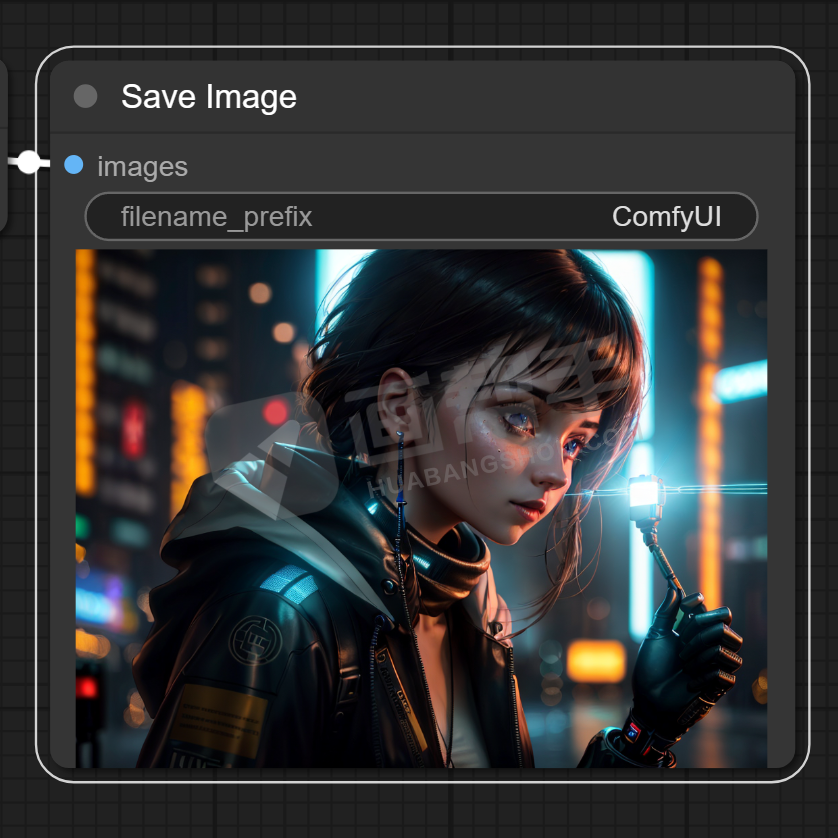
放大一下看看,和webUI的成图效果没有什么区别。

总结
ComfyUI有着更轻便的系统和更亲民的配置需求,节点化的操作也能实现更多的可能性。
就目前而言,我个人比较建议ComfyUI和WebUI共存的形式,配合起来使用,反正也可以共享模型文件,不会占用多大的硬盘空间。
这样我们可以逐渐了解ComfyUI的使用逻辑和SD底层架构,而WebUI有着完善的配套环境,各种插件已经非常成熟,目前来讲还是更具备生产力一些。
原文链接:https://www.huabangshou.com/3850.html,转载请注明出处~~~




评论0